프론트엔드 개발자의 TIL #004
TIL #004
191107 목
오늘은 교내 DSC(Developer Student Club)에서 진행한 코드랩 실습에 참여했다. 그래서 플러터 대신 갑분머신러닝.. 내가 좀 더 관심있는 분야이기도 하고, 추천시스템의 기반이 될 수 있는 공부이기 때문에 여러모로 그래노라에도 도움이 될 것 같다.
오늘 배운 점
<Hello World! from Tensorflow>
1. Machine Learning
기존의 프로그래밍이 규칙과 데이터를 입력하여 답을 출력하는 방식이었다면, 머신러닝은 규칙을 직접 입력하지 않고, 입력한 데이터와 답(label)을 토대로 프로그램이 직접 유추하게 한다. 이렇게 생성된 규칙이 적용된 모형을 Model이라 하고, 이를 통해 예측값을 도출한다.
2. 설정
import tensorflow as tf
import numpy as np
from tensorflow import kerasimport로 필요한 library를 가져온다. numpy는 데이터를 배열로 잘 정리해주고, keras는 머신러닝 신경망의 계층을 잘 표현할 수 있게 해준다. (Tensorflow는 2.XX 이상의 버전이어야 한다)
3. 모델 정의 및 컴파일
model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])
model.compile(optimizer='sgd', loss='mean_squared_error')실습에서 사용된 SGD(Stochastic Gradient Descent)는 확률적 경사하강법으로, 손실함수의 기울기를 계산하여 기울기값에 학습률(Learning Rate)를 계산한 결과로 가중치를 갱신한다.

model.fit(xs, ys, epochs=500) //epoch=훈련 횟수numpy를 이용해 데이터 배열을 만들어주고, 모델을 적합시킨다. n년 째 통계 전공에서 decision tree, random forest, LPM/logit/probit 등 다양한 모델에 fitting을 해보았지만, 텐서플로우로 신경망(Neural Network)을 형성해본 적은 처음이라 재밌었다.

print(model.predict([10.0]))
[[31.005257]] //31에 가까운 값으로 도출된다.배열에 의도한 규칙대로라면, x=10일 때 y=31이어야 한다. 하지만 예시로 만든 배열은 길이가 5밖에 되지 않기 때문에 정확히 31로 예측을 하진 못하지만, 점점 31에 가까운 값으로 다가간다.
<Image Recognition>
1. Computer Vision
그 다음 실습은 10가지 의류 형태를 학습하여 인식, 분류하는 컴퓨터 비전을 만들어 보는 것이었다. 말 그대로 기계의 시각을 연구하는 분야인데, 기계 학습과 인공지능을 포함한 영상 처리, 물체 및 패턴 인식 등을 수행한다.

2. 데이터 불러오기
//데이터
mnist = tf.keras.datasets.fashion_mnist
//Cross Validation을 위한 학습 데이터(train)와 테스트 데이터(test)
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
import matplotlib.pyplot as plt
plt.imshow(training_images[0])
print(training_labels[0])
print(training_images[0])컴퓨터가 어떤식으로 이미지를 인식하는지 간접적으로나마 확인할 수 있다. (0~255까지의 숫자로 이미지 구성)


//normalization
training_images = training_images / 255.0
test_images = test_images / 255.00~255 범위를 정규화를 거쳐 0~1로 만들어준다.
3. 모델 정의
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])-
Sequential: 신경망에서 layer의 순서를 정해준다.
-
Flatten: 정사각형으로 출력되는 이미지를 1차원 벡터로 바꿔준다.
-
Dense: 뉴런 층을 추가해준다. 각 layer에 activation function으로 수행할 일을 지시한다. 여기서는 Relu와 Softmax를 사용하기로 한다.
-
Relu는 Rectified Linear Unit으로, 입력값이 0보다 작으면 0, 0보다 크면 입력값 그대로를 내보낸다. 선형 함수이기 때문에 미분 계산이 용이하고, 0 이하의 값을 처리하여 부분적인 활성화가 가능하다는 장점이 있다.
-
Softmax는 정규화를 거쳐 분류할 때 최댓값을 효과적으로 선택하는 데 사용된다. logit 함수의 역함수인 sigmoid 함수를 k개 class로 일반화하면 유도되는 함수이다.
4. 모델 컴파일 및 훈련
//모델 빌딩
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5)-
정확도(accuracy)를 매개 변수로 사용하여 훈련이 테스트 데이터를 얼마나 정확하게 예측하는지 확인할 수 있다.
-
Adam은 Momentum과 AdaGrad를 섞은 방법으로, 학습률을 줄여나가고 속도를 계산하여 학습의 갱신 강도를 조정해나간다.

5회의 훈련만으로 89%의 정확도가 나온다.
5. 모델 평가
model.evaluate(test_images, test_labels)classifications = model.predict(test_images)
print(classifications[0])
//softmax에서 확률의 최댓값을 찾아서 도출
print(test_labels[0])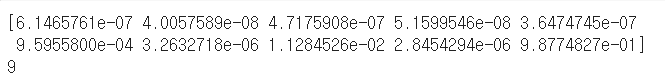
6. Callback
훈련을 하는 데에는 시간이 걸리는데, 효율적인 기계 학습을 위해 Callback을 사용한다. 원하는 수준의 정확도가 나왔을 때 훈련을 중단할 수 있다. 여기서는 95%의 정확도를 넘어가면 훈련을 중단하는 것으로 설정해두었다.
class myCallback(tf.keras.callbacks.Callback): //정확도가 95%를 넘어가면 훈련 종료
def on_epoch_end(self, epoch, logs={}):
if(logs.get('acc')>0.95):
print("\nReached 95% accuracy so cancelling training!")
self.model.stop_training = True
callbacks = myCallback()
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images=training_images/255.0
test_images=test_images/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=15, callbacks=[callbacks])
//15회의 훈련중 95%를 초과하면 횟수를 채우지 않고 종료한다.
참고 링크:
https://colab.research.google.com/notebooks/welcome.ipynb?hl=ko
내일 배울 것
<Flutter>
1. 다시 플러터로 돌아가서 소셜 로그인 도전
2. 댓글 작성 등의 SNS 기능 추가적으로 구현
- 파이썬은 압도적으로 쉽다(..)
- 프론트엔드 개발하며 꾸는 데이터 사이언스의 꿈